Hola, mi nombre es
Luciano Espejo.
Data Scients.
Soy un profesional entusiasta por el análisis de datos. Busco oportunidades para desarrollar mi carrera en el rol junior de ciencia de datos, donde pueda aplicar mis conocimientos técnicos para limpiar, procesar y analizar conjuntos de datos, así como generar visualizaciones claras que comuniquen insights estratégicos
01. Sobre Mí
¡Hola! Mi nombre es Luciano Espejo y disfruto transformar datos en historias que impactan. Mi interés por la ciencia de los datos nació durante los primeros años de la carrera de Lic. en Ciencias de la Computación, cuando descubrí que detrás de cada conjunto de números podía haber patrones, decisiones importantes, e incluso soluciones a problemas reales.
Desde entonces, me atrapó todo el proceso: desde limpiar y procesar datos, hasta construir visualizaciones que realmente cuenten algo. Con el tiempo, fui aprendiendo a usar herramientas como Python, Pandas, SQL y librerías de visualización para explorar datos, y descubrí que lo que más me motiva es generar valor a partir de la información.
Hoy, en mi quinto año de carrera, estoy buscando oportunidades como junior o trainee en ciencia de datos, donde pueda seguir creciendo, aportar mis habilidades y aprender en entornos reales.
Más allá del código, me gusta entender el “por qué” de las cosas, comunicar ideas con claridad, y trabajar en equipo para resolver desafíos.

02. Habilidades
A lo largo de mi carrera universitaria y proyectos personales he adquirido experiencia en distintas áreas del análisis de datos y el desarrollo web backend, lo que me permite abordar soluciones completas desde la recolección y limpieza de datos hasta su visualización e implementación en aplicaciones funcionales.
Mi enfoque es crear código limpio, mantenible y eficiente que proporcione la mejor experiencia posible tanto para los usuarios como para mis compañeros desarrolladores.
Ciencia de datos
- Python para análisis de datos
- Pandas, Numpy
- Matplotlib, Seaborn, Plotly
- Análisis exploratorio de datos (EDA)
Desarrollo Backend
- Python
- Flask
- Django
- SQL (PostgresSQL, SQLServer)
Interfaces Gráficas
- Tkinter
- CustomTkinter
Visualización y Presentación de datos
- Dash (Plotly)
- Power BI (básico)
- Figma
Herramientas y Entorno
- Visual Studio
- Git/GitHub
- Postman
- Google Colab
Habilidades Blandas
- Trabajo en equipo
- Pensamiento analítico
- Resolución de problemas
- Adaptabilidad
- Autonomía y aprendizaje continuo
- Metodologías ágiles
03. Práctica Profecional
Proyecto Destacado
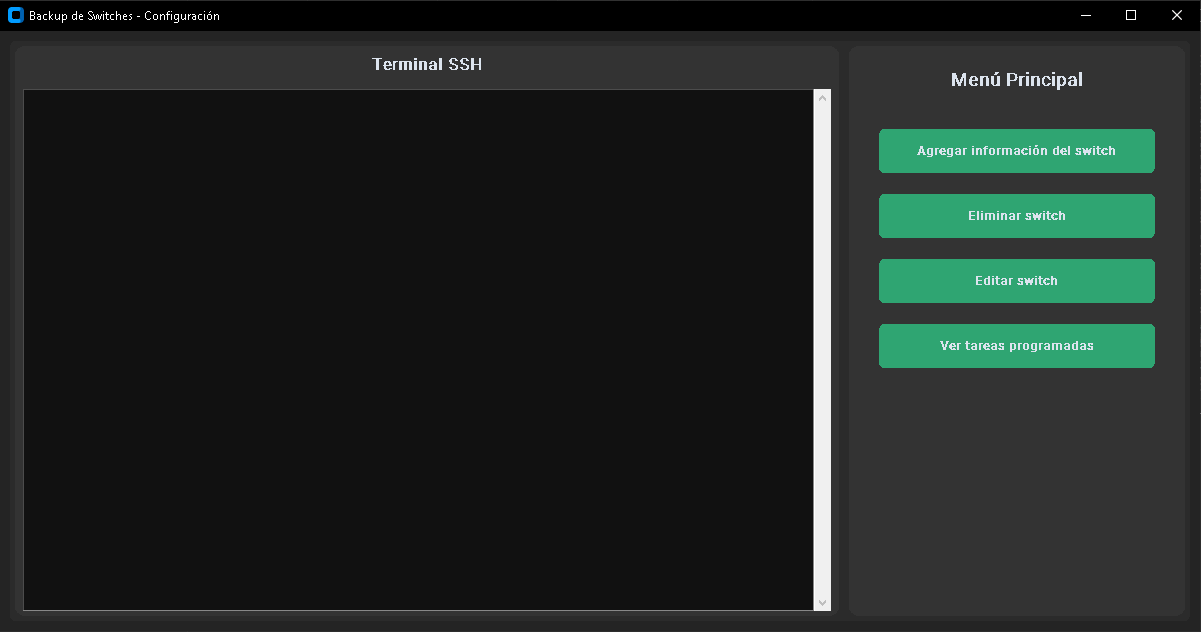
Backup para Switches – Minera Gualcamayo
Aplicación de escritorio para realizar copias de seguridad automáticas de la configuración de switches Cisco. Permite gestionar múltiples dispositivos, realizar backups programados y restaurar configuraciones fácilmente.
- Python
- CustomTkinter
- FTP
- SSH
- GUI
Proyecto Destacado
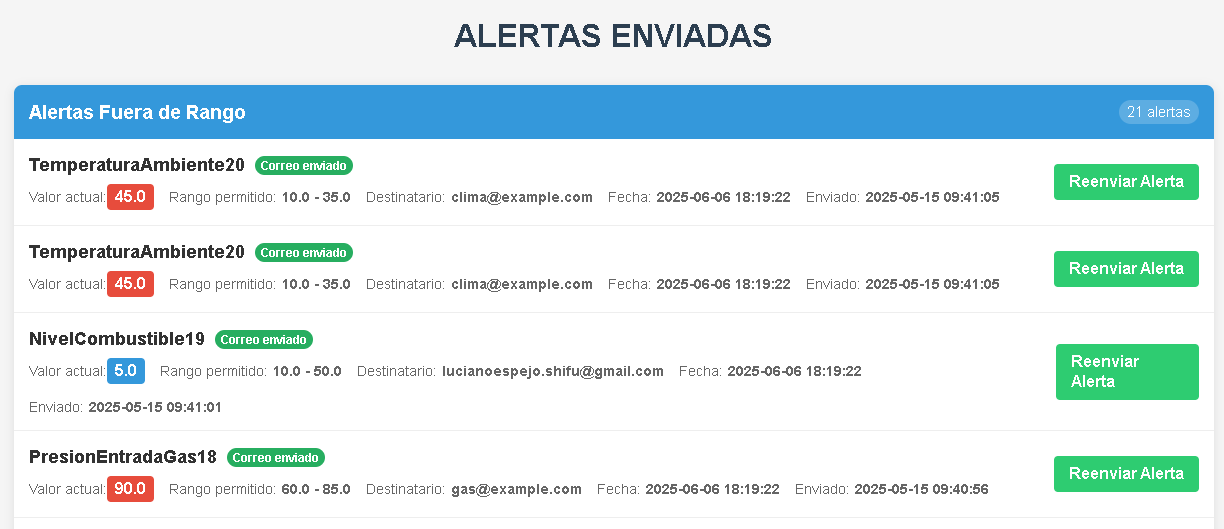
Sistema de Alarmas - Minera Gualcamayo
Desarrollé un sistema que automatiza el envío de notificaciones por email ante eventos críticos registrados en la base de datos. Incluye control de errores, registro de auditoría y visualización de métricas a través de un dashboard interactivo.
- Python
- Pandas
- Dash/Plotly
- SMTP
- SQLServer
Proyecto Destacado
Análisis de la rotación de empleados
Desarrollo de un sistema predictivo para identificar empleados con alto riesgo de abandonar la empresa, permitiendo implementar estrategias de retención tempranas
- Python
- Pandas
- Numpy
- Scikit-learn
- Matplotlib

Proyectos Adicionales
Predicción de Resultados de Partidos de Fútbol
Proyecto en desarrollo orientado a predecir los resultados de partidos de fútbol a partir de datos históricos. Se aplican técnicas de análisis exploratorio, limpieza y modelado con regresión para estimar variables clave como goles o puntos.
- Python
- Pandas
- Jupyter Notebook
Análisis Estadístico de Datos Médicos
Aplicación en consola que permite explorar un dataset médico mediante visualizaciones, pruebas de hipótesis, regresión lineal e intervalos de confianza, integrando análisis descriptivo e inferencial.
- Python
- Pandas - Numpy - Seaborn
- Análisis de datos · Estadística inferencial
Compresor Shannon-BWT
Desarrollé un compresor de texto que aplica la Transformación Burrows-Wheeler seguida de una codificación Shannon con modelo de Markov de orden 2. El sistema permite comprimir y descomprimir archivos, conservando la integridad del texto original y mostrando estadísticas de compresión.
- Python
- Shannon Coding - Burrows-Wheeler
- Modelos de Markov
Sistema de Gestión de Restaurante
Este proyecto implementa un sistema completo de gestión de pedidos para un restaurante, con control de usuarios (mozos y cocineros), carga de pedidos, control de productos y seguimiento del estado de cada ítem. El sistema permite registrar, listar, cobrar y actualizar pedidos, con una estructura modular basada en Flask y SQLAlchemy.
- Python
- Flask
- Flask-SQLAlchemy
- SQLite
04. ¿Y ahora qué?
Ponte en Contacto
¿Tienes una pregunta, propuesta o simplemente quieres saludar? ¡Envíame un mensaje y te responderé lo antes posible!
NOTA: El correo será enviado a mi correo personal